Blogged Answers: A (Mostly) Complete Guide to React Rendering Behavior
This is a post in the Blogged Answers series.
I've seen a lot of ongoing confusion over when, why, and how React will re-render components, and how use of Context and React-Redux will affect the timing and scope of those re-renders. After having typed up variations of this explanation dozens of times, it seems it's worth trying to write up a consolidated explanation that I can refer people to. Note that all this information is available online already, and has been explained in numerous other excellent blog posts and articles, several of which I'm linking at the end in the "Further Information" section for reference. But, people seem to be struggling to put the pieces together for a full understanding, so hopefully this will help clarify things for someone.
Note: Updated October 2022 to cover React 18 and future React updates
I also did a talk based on this post for React Advanced 2022:
React Advanced 2022 - A (Brief) Guide to React Rendering Behavior
Table of Contents 🔗︎
- What is "Rendering"?
- How Does React Handle Renders?
- Improving Rendering Performance
- Context and Rendering Behavior
- React-Redux and Rendering Behavior
- Future React Improvements
- Summary
- Final Thoughts
- Further Information
What is "Rendering"? 🔗︎
Rendering is the process of React asking your components to describe what they want their section of the UI to look like, now, based on the current combination of props and state.
Rendering Process Overview 🔗︎
During the rendering process, React will start at the root of the component tree and loop downwards to find all components that have been flagged as needing updates. For each flagged component, React will call either FunctionComponent(props) (for function components), or classComponentInstance.render() (for class components) , and save the render output for the next steps of the render pass.
A component's render output is normally written in JSX syntax, which is then converted to React.createElement() calls as the JS is compiled and prepared for deployment. createElement returns React elements, which are plain JS objects that describe the intended structure of the UI. Example:
// This JSX syntax:
return <MyComponent a={42} b="testing">Text here</MyComponent>
// is converted to this call:
return React.createElement(MyComponent, {a: 42, b: "testing"}, "Text Here")
// and that becomes this element object:
{type: MyComponent, props: {a: 42, b: "testing"}, children: ["Text Here"]}
// And internally, React calls the actual function to render it:
let elements = MyComponent({...props, children})
// For "host components" like HTML:
return <button onClick={() => {}}>Click Me</button>
// becomes
React.createElement("button", {onClick}, "Click Me")
// and finally:
{type: "button", props: {onClick}, children: ["Click me"]}
After it has collected the render output from the entire component tree, React will diff the new tree of objects (frequently referred to as the "virtual DOM"), and collects a list of all the changes that need to be applied to make the real DOM look like the current desired output. The diffing and calculation process is known as "reconciliation".
React then applies all the calculated changes to the DOM in one synchronous sequence.
Note: The React team has downplayed the term "virtual DOM" in recent years. Dan Abramov said:
I wish we could retire the term “virtual DOM”. It made sense in 2013 because otherwise people assumed React creates DOM nodes on every render. But people rarely assume this today. “Virtual DOM” sounds like a workaround for some DOM issue. But that’s not what React is.
React is “value UI”. Its core principle is that UI is a value, just like a string or an array. You can keep it in a variable, pass it around, use JavaScript control flow with it, and so on. That expressiveness is the point — not some diffing to avoid applying changes to the DOM.
It doesn’t even always represent the DOM, for example<Message recipientId={10} />is not DOM. Conceptually it represents lazy function calls:Message.bind(null, { recipientId: 10 }).
Render and Commit Phases 🔗︎
The React team divides this work into two phases, conceptually:
- The "Render phase" contains all the work of rendering components and calculating changes
- The "Commit phase" is the process of applying those changes to the DOM
After React has updated the DOM in the commit phase, it updates all refs accordingly to point to the requested DOM nodes and component instances. It then synchronously runs the componentDidMount and componentDidUpdate class lifecycle methods, and the useLayoutEffect hooks.
React then sets a short timeout, and when it expires, runs all the useEffect hooks. This step is also known as the "Passive Effects" phase.
React 18 added "Concurrent Rendering" features like useTransition. This gives React the ability to pause the work in the rendering phase to allow the browser to process events. React will either resume, throw away, or recalculate that work later as appropriate. Once the render pass has been completed, React will still run the commit phase synchronously in one step.
A key part of this to understand is that "rendering" is not the same thing as "updating the DOM", and a component may be rendered without any visible changes happening as a result. When React renders a component:
- The component might return the same render output as last time, so no changes are needed
- In Concurrent Rendering, React might end up rendering a component multiple times, but throw away the render output each time if other updates invalidate the current work being done
This excellent interactive React hooks timeline diagram helps illustrate the sequencing of rendering, committing, and executing hooks:
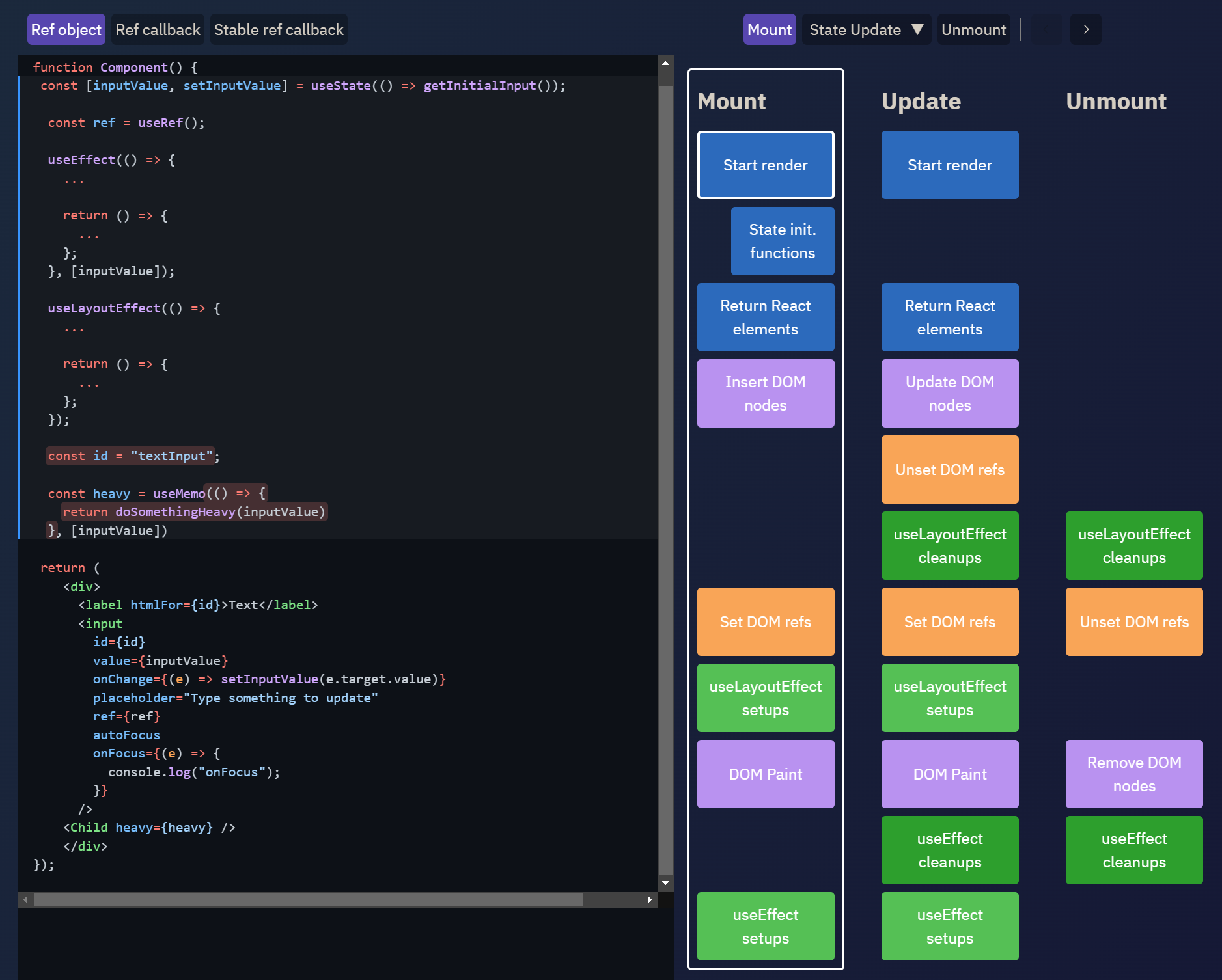
For additional visualizations, see:
- React hooks flow diagram
- React hooks render/commit phase diagram
- React class lifecycle methods diagram
How Does React Handle Renders? 🔗︎
Queuing Renders 🔗︎
After the initial render has completed, there are a few different ways to tell React to queue a re-render:
- Function components:
useStatesettersuseReducerdispatches
- Class components:
this.setState()this.forceUpdate()
- Other:
- Calling the ReactDOM top-level
render(<App>)method again (which is equivalent to callingforceUpdate()on the root component) - Updates triggered from the new
useSyncExternalStorehook
- Calling the ReactDOM top-level
Note that function components don't have a forceUpdate method, but you can get the same behavior by using a useReducer hook that always increments a counter:
const [, forceRender] = useReducer((c) => c + 1, 0);
Standard Render Behavior 🔗︎
It's very important to remember that:
React's default behavior is that when a parent component renders, React will recursively render all child components inside of it!
As an example, say we have a component tree of A > B > C > D, and we've already shown them on the page. The user clicks a button in B that increments a counter:
- We call
setState()inB, which queues a re-render of B. - React starts the render pass from the top of the tree
- React sees that
Ais not marked as needing an update, and moves past it - React sees that
Bis marked as needing an update, and renders it.Breturns<C />as it did last time. Cwas not originally marked as needing an update. However, because its parentBrendered, React now moves downwards and rendersCas well. C returns<D />again.Dwas also not marked for rendering, but since its parentCrendered, React moves downward and rendersDtoo.
To repeat this another way:
Rendering a component will, by default, cause all components inside of it to be rendered too!
Also, another key point:
In normal rendering, React does not care whether "props changed" - it will render child components unconditionally just because the parent rendered!
This means that calling setState() in your root <App> component, with no other changes altering the behavior, will cause React to re-render every single component in the component tree. After all, one of the original sales pitches for React was "act like we're redrawing the entire app on every update".
Now, it's very likely that most of the components in the tree will return the exact same render output as last time, and therefore React won't need to make any changes to the DOM. But, React will still have to do the work of asking components to render themselves and diffing the render output. Both of those take time and effort.
Remember, rendering is not a bad thing - it's how React knows whether it needs to actually make any changes to the DOM!
Rules of React Rendering 🔗︎
One of the primary rules of React rendering is that rendering must be "pure" and not have any side effects!
This can be tricky and confusing, because many side effects are not obvious, and don't result in anything breaking. For example, strictly speaking a console.log() statement is a side effect, but it won't actually break anything. Mutating a prop is definitely a side effect, and it might not break anything. Making an AJAX call in the middle of rendering is also definitely a side effect, and can definitely cause unexpected app behavior depending on the type of request.
Sebastian Markbage wrote an excellent document entitled The Rules of React. In it, he defines the expected behaviors for different React lifecycle methods, including render, and what kinds of operations would be considered safely "pure" and which would be unsafe. It's worth reading that in its entirety, but I'll summarize the key points:
- Render logic must not:
- Can't mutate existing variables and objects
- Can't create random values like
Math.random()orDate.now() - Can't make network requests
- Can't queue state updates
- Render logic may:
- Mutate objects that were newly created while rendering
- Throw errors
- "Lazy initialize" data that hasn't been created yet, such as a cached value
Component Metadata and Fibers 🔗︎
React stores an internal data structure that tracks all the current component instances that exist in the application. The core piece of this data structure is an object called a "fiber", which contains metadata fields that describe:
- What component type is supposed to be rendered at this point in the component tree
- The current props and state associated with this component
- Pointers to parent, sibling, and child components
- Other internal metadata that React uses to track the rendering process
If you've ever heard the phrase "React Fiber" used to describe a React version or feature, that's really referring to the rewrite of React's internals that switched the rendering logic to rely on these "Fiber" objects as the key data structure. That was released as React 16.0, so every version of React since then has used this approach.
The shortened version of the Fiber type looks like:
export type Fiber = {
// Tag identifying the type of fiber.
tag: WorkTag;
// Unique identifier of this child.
key: null | string;
// The resolved function/class/ associated with this fiber.
type: any;
// Singly Linked List Tree Structure.
child: Fiber | null;
sibling: Fiber | null;
index: number;
// Input is the data coming into this fiber (arguments/props)
pendingProps: any;
memoizedProps: any; // The props used to create the output.
// A queue of state updates and callbacks.
updateQueue: Array<State | StateUpdaters>;
// The state used to create the output
memoizedState: any;
// Dependencies (contexts, events) for this fiber, if any
dependencies: Dependencies | null;
};
(You can see the full definition of the Fiber type as of React 18 here.)
During a rendering pass, React will iterate over this tree of fiber objects, and construct an updated tree as it calculates the new rendering results.
Note that these "fiber" objects store the real component props and state values. When you use props and state in your components, React is actually giving you access to the values that were stored on the fiber objects. In fact, for class components specifically, React explicitly copies componentInstance.props = newProps over to the component right before rendering it. So, this.props does exist, but it only exists because React copied the reference over from its internal data structures. In that sense, components are sort of a facade over React's fiber objects.
Similarly, React hooks work because React stores all of the hooks for a component as a linked list attached to that component's fiber object. When React renders a function component, it gets that linked list of hook description entries from the fiber, and every time you call another hook, it returns the appropriate values that were stored in the hook description object (like the state and dispatch values for useReducer.
When a parent component renders a given child component for the first time, React creates a fiber object to track that "instance" of a component. For class components, it literally calls const instance = new YourComponentType(props) and saves the actual component instance onto the fiber object. For function components, React just calls YourComponentType(props) as a function.
Component Types and Reconciliation 🔗︎
As described in the "Reconciliation" docs page, React tries to be efficient during re-renders, by reusing as much of the existing component tree and DOM structure as possible. If you ask React to render the same type of component or HTML node in the same place in the tree, React will reuse that and just apply updates if appropriate, instead of re-creating it from scratch. That means that React will keep component instances alive as long as you keep asking React to render that component type in the same place. For class components, it actually does use the same actual instance of your component. A function component has no true "instance" the way a class does, but we can think of <MyFunctionComponent /> as representing an "instance" in terms of "a component of this type is being shown here and kept alive".
So, how does React know when and how the output has actually changed?
React's rendering logic compares elements based on their type field first, using === reference comparisons. If an element in a given spot has changed to a different type, such as going from <div> to <span> or <ComponentA> to <ComponentB>, React will speed up the comparison process by assuming that entire tree has changed. As a result, React will destroy that entire existing component tree section, including all DOM nodes, and recreate it from scratch with new component instances.
This means that you must never create new component types while rendering! Whenever you create a new component type, it's a different reference, and that will cause React to repeatedly destroy and recreate the child component tree.
In other words, don't do this:
// ❌ BAD!
// This creates a new `ChildComponent` reference every time!
function ParentComponent() {
function ChildComponent() {
return <div>Hi</div>;
}
return <ChildComponent />;
}
Instead, always define components separately:
// ✅ GOOD
// This only creates one component type reference
function ChildComponent() {
return <div>Hi</div>;
}
function ParentComponent() {
return <ChildComponent />;
}
Keys and Reconciliation 🔗︎
The other way that React identifies component "instances" is via the key pseudo-prop. React uses key as a unique identifier that it can use to differentiate specific instances of a component type.
Note that key isn't actually a real prop - it's an instruction to React. React will always strip that off, and it will never be passed through to the actual component, so you can never have props.key - it will always be undefined.
The main place we use keys is rendering lists. Keys are especially important here if you are rendering data that may be changed in some way, such as reordering, adding, or deleting list entries. It's particularly important here that keys should be some kind of unique IDs from your data if at all possible - only use array indices as keys as a last resort fallback!
// ✅ Use a data object ID as the key for list items
todos.map((todo) => <TodoListItem key={todo.id} todo={todo} />);
Here's an example of why this matters. Say I render a list of 10 <TodoListItem> components, using array indices as keys. React sees 10 items, with keys of 0..9. Now, if we delete items 6 and 7, and add three new entries at the end, we end up rendering items with keys of 0..10. So, it looks to React like I really just added one new entry at the end because we went from 10 list items to 11. React will happily reuse the existing DOM nodes and component instances. But, that means that we're probably now rendering <TodoListItem key={6}> with the todo item that was being passed to list item #8. So, the component instance is still alive, but now it's getting a different data object as a prop than it was previously. This may work, but it may also produce unexpected behavior. Also, React will now have to go apply updates to several of the list items to change the text and other DOM contents, because the existing list items are now having to show different data than before. Those updates really shouldn't be necessary here, since none of those list items changed.
If instead we were using key={todo.id} for each list item, React will correctly see that we deleted two items and added three new ones. It will destroy the two deleted component instances and their associated DOM, and create three new component instances and their DOM. This is better than having to unnecessarily update the components that didn't actually change.
Keys are useful for component instance identity beyond lists as well. You can add a key to any React component at any time to indicate its identity, and changing that key will cause React to destroy the old component instance and DOM and create new ones. A common use case for this is a list + details form combination, where the form shows the data for the currently selected list item. Rendering <DetailForm key={selectedItem.id}> will cause React to destroy and re-create the form when the selected item changes, thus avoiding any issues with stale state inside the form.
Render Batching and Timing 🔗︎
By default, each call to setState() causes React to start a new render pass, execute it synchronously, and return. However, React also applies a sort of optimization automatically, in the form of render batching. Render batching is when multiple calls to setState() result in a single render pass being queued and executed, usually on a slight delay.
The React community often describes this as "state updates may be asynchronous". The new React docs also describe it as "State is a Snapshot". That's a reference to this render batching behavior.
In React 17 and earlier, React only did batching in React event handlers such as onClick callbacks. Updates queued outside of event handlers, such as in a setTimeout, after an await, or in a plain JS event handler, were not queued, and would each result in a separate re-render.
However, React 18 now does "automatic batching" of all updates queued in any single event loop tick. This helps cut down on the overall number of renders needed.
Let's look at a specific example.
const [counter, setCounter] = useState(0);
const onClick = async () => {
setCounter(0);
setCounter(1);
const data = await fetchSomeData();
setCounter(2);
setCounter(3);
};
With React 17, this executed three render passes. The first pass will batch together setCounter(0) and setCounter(1), because both of them are occurring during the original event handler call stack, and so they're both occurring inside the unstable_batchedUpdates() call.
However, the call to setCounter(2) is happening after an await. This means the original synchronous call stack is done, and the second half of the function is running much later in a totally separate event loop call stack. Because of that, React will execute an entire render pass synchronously as the last step inside the setCounter(2) call, finish the pass, and return from setCounter(2).
The same thing will then happen for setCounter(3), because it's also running outside the original event handler, and thus outside the batching.
However, with React 18, this executes two render passes. The first two, setCounter(0) and setCounter(1), are batched together because they're in one event loop tick. Later, after the await, both setCounter(2) and setCounter(3) are batched together - even though they're much later, that's also two state updates queued in the same event loop, so they get batched into a second render.
Async Rendering, Closures, and State Snapshots 🔗︎
One extremely common mistake we see all the time is when a user sets a new value, then tries to log the existing variable name. However, the original value gets logged, not the updated value.
function MyComponent() {
const [counter, setCounter] = useState(0);
const handleClick = () => {
setCounter(counter + 1);
// ❌ THIS WON'T WORK!
console.log(counter);
// Original value was logged - why is this not updated yet??????
};
}
So, why doesn't this work?
As mentioned above, it's common for experienced users to say "React state updates are async". This is sort of true, but there's a bit more nuance then that, and actually a couple different problems at work here.
Strictly speaking, the React render is literally synchronous - it will be executed in a "microtask" at the very end of this event loop tick. (This is admittedly being pedantic, but the goal of this article is exact details and clarity.) However, yes, from the point of view of that handleClick function, it's "async" in that you can't immediately see the results, and the actual update occurs much later than the setCounter() call.
However, there's a bigger reason why this doesn't work. The handleClick function is a "closure" - it can only see the values of variables as they existed when the function was defined. In other words, these state variables are a snapshot in time.
Since handleClick was defined during the most recent render of this function component, it can only see the value of counter as it existed during that render pass. When we call setCounter(), it queues up a future render pass, and that future render will have a new counter variable with the new value and a new handleClick function... but this copy of handleClick will never be able to see that new value.
The new React docs cover this in more detail in the section State as a Snapshot, which is highly recommended reading.
Going back to the original example: trying to use a variable right after you set an updated value is almost always the wrong approach, and suggests you need to rethink how you are trying to use that value.
Render Behavior Edge Cases 🔗︎
Commit Phase Lifecycles 🔗︎
There's some additional edge cases inside of the commit-phase lifecycle methods: componentDidMount, componentDidUpdate, and useLayoutEffect. These largely exist to allow you to perform additional logic after a render, but before the browser has had a chance to paint. In particular, a common use case is:
- Render a component the first time with some partial but incomplete data
- In a commit-phase lifecycle, use refs to measure the real size of the actual DOM nodes in the page
- Set some state in the component based on those measurements
- Immediately re-render with the updated data
In this use case, we don't want the initial "partial" rendered UI to be visible to the user at all - we only want the "final" UI to show up. Browsers will recalculate the DOM structure as it's being modified, but they won't actually paint anything to the screen while a JS script is still executing and blocking the event loop. So, you can perform multiple DOM mutations, like div.innerHTML = "a"; div.innerHTML = b";, and the "a" will never appear.
Because of this, React will always run renders in commit-phase lifecycles synchronously. That way, if you do try to perform an update like that "partial->final" switch, only the "final" content will ever be visible on screen.
As far as I know, state updates in useEffect callbacks are queued up, and flushed at the end of the "Passive Effects" phase once all the useEffect callbacks have completed.
Reconciler Batching Methods 🔗︎
React reconcilers (ReactDOM, React Native) have methods to alter render batching.
For React 17 and earlier, you can wrap multiple updates that are outside of event handlers in unstable_batchedUpdates() to batch them together. (Note that despite the unstable_ prefix, it's heavily used and depended on by code at Facebook and public libraries - React-Redux v7 used unstable_batchedUpdates internally)
Since React 18 automatically batches by default, React 18 has a flushSync() API that you can use to force immediate renders and opt out of automatic batching.
Note that since these are reconciler-specific APIs, alternate reconcilers like react-three-fiber and ink may not have them exposed. Check the API declarations or implementation details to see what's available.
<StrictMode> 🔗︎
React will double-render components inside of a <StrictMode> tag in development. That means the number of times your rendering logic runs is not the same as the number of committed render passes, and you cannot rely on console.log() statements while rendering to count the number of renders that have occurred. Instead, either use the React DevTools Profiler to capture a trace and count the number of committed renders overall, or add logging inside of a useEffect hook or componentDidMount/Update lifecycle. That way the logs will only get printed when React has actually completed a render pass and committed it.
Setting State While Rendering 🔗︎
In normal situations, you should never queue a state update while in the actual rendering logic. In other words, it's fine to create a click callback that will call setSomeState() when the click happens, but you should not call setSomeState() as part of the actual rendering behavior.
However, there is one exception to this. Function components may call setSomeState() directly while rendering, as long as it's done conditionally and isn't going to execute every time this component renders. This acts as the function component equivalent of getDerivedStateFromProps in class components. If a function component queues a state update while rendering, React will immediately apply the state update and synchronously re-render that one component before moving onwards. If the component infinitely keeps queueing state updates and forcing React to re-render it, React will break the loop after a set number of retries and throw an error (currently 50 attempts). This technique can be used to immediately force an update to a state value based on a prop change, without requiring a re-render + a call to setSomeState() inside of a useEffect.
Improving Rendering Performance 🔗︎
Although renders are the normal expected part of how React works, it's also true that that render work can be "wasted" effort at times. If a component's render output didn't change, and that part of the DOM didn't need to be updated, then the work of rendering that component was really kind of a waste of time.
React component render output should always be entirely based on current props and current component state. Therefore, if we know ahead of time that a component's props and state haven't changed, we should also know that the render output would be the same, that no changes are necessary for this component, and that we can safely skip the work of rendering it.
When trying to improve software performance in general, there are two basic approaches: 1) do the same work faster, and 2) do less work. Optimizing React rendering is primarily about doing less work by skipping rendering components when appropriate.
Component Render Optimization Techniques 🔗︎
React offers three primary APIs that allow us to potentially skip rendering a component:
The primary method is React.memo(), a built-in "higher order component" type. It accepts your own component type as an argument, and returns a new wrapper component. The wrapper component's default behavior is to check to see if any of the props have changed, and if not, prevent a re-render. Both function components and class components can be wrapped using React.memo(). (A custom comparison callback may be passed in, but it really can only compare the old and new props anyway, so the main use case for a custom compare callback would be only comparing specific props fields instead of all of them.)
The other options are:
React.Component.shouldComponentUpdate: an optional class component lifecycle method that will be called early in the render process. If it returnsfalse, React will skip rendering the component. It may contain any logic you want to use to calculate that boolean result, but the most common approach is to check if the component's props and state have changed since last time, and returnfalseif they're unchanged.React.PureComponent: since that comparison of props and state is the most common way to implementshouldComponentUpdate, thePureComponentbase class implements that behavior by default, and may be used instead ofComponent+shouldComponentUpdate.
All of these approaches use a comparison technique called "shallow equality". This means checking every individual field in two different objects, and seeing if any of the contents of the objects are a different value. In other words, obj1.a === obj2.a && obj1.b === obj2.b && ......... This is typically a fast process, because === comparisons are very simple for the JS engine to do. So, these three approaches do the equivalent of const shouldRender = !shallowEqual(newProps, prevProps).
There's also a lesser-known technique as well: if a React component returns the exact same element reference in its render output as it did the last time, React will skip re-rendering that particular child. There's at least a couple ways to implement this technique:
- If you include
props.childrenin your output, that element is the same if this component does a state update - If you wrap some elements with
useMemo(), those will stay the same until the dependencies change
Examples:
// The `props.children` content won't re-render if we update state
function SomeProvider({ children }) {
const [counter, setCounter] = useState(0);
return (
<div>
<button onClick={() => setCounter(counter + 1)}>Count: {counter}</button>
<OtherChildComponent />
{children}
</div>
);
}
function OptimizedParent() {
const [counter1, setCounter1] = useState(0);
const [counter2, setCounter2] = useState(0);
const memoizedElement = useMemo(() => {
// This element stays the same reference if counter 2 is updated,
// so it won't re-render unless counter 1 changes
return <ExpensiveChildComponent />;
}, [counter1]);
return (
<div>
<button onClick={() => setCounter1(counter1 + 1)}>
Counter 1: {counter1}
</button>
<button onClick={() => setCounter1(counter2 + 1)}>
Counter 2: {counter2}
</button>
{memoizedElement}
</div>
);
}
Conceptually, we could say that the difference between these two approaches is:
React.memo(): controlled by the child component- Same-element references: controlled by the parent component
For all of these techniques, skipping rendering a component means React will also skip rendering that entire subtree, because it's effectively putting a stop sign up to halt the default "render children recursively" behavior.
How New Props References Affect Render Optimizations 🔗︎
We've already seen that by default, React re-renders all nested components even if their props haven't changed. That also means that passing new references as props to a child component doesn't matter, because it will render whether or not you pass the same props. So, something like this is totally fine:
function ParentComponent() {
const onClick = () => {
console.log('Button clicked');
};
const data = { a: 1, b: 2 };
return <NormalChildComponent onClick={onClick} data={data} />;
}
Every time ParentComponent renders, it will create a new onClick function reference and a new data object reference, then pass them as props to NormalChildComponent. (Note that it doesn't matter whether we're defining onClick using the function keyword or as an arrow function - it's a new function reference either way.)
That also means there's no point in trying to optimize renders for "host components" like a <div> or a <button> by wrapping them up in a React.memo(). There's no child component underneath those basic components, so the rendering process would stop there anyway.
However, if the child component is trying to optimize renders by checking to see whether props have changed, then passing new references as props will cause the child to render. If the new prop references are actually new data, this is good. However, what if the parent component is just passing down a callback function?
const MemoizedChildComponent = React.memo(ChildComponent);
function ParentComponent() {
const onClick = () => {
console.log('Button clicked');
};
const data = { a: 1, b: 2 };
return <MemoizedChildComponent onClick={onClick} data={data} />;
}
Now, every time ParentComponent renders, these new references are going to cause MemoizedChildComponent to see that its props values have changed to new references, and it will go ahead and re-render... even though the onClick function and the data object should be basically the same thing every time!
This means that:
MemoizedChildComponentwill always re-render even though we wanted to skip rendering most of the time- The work that it's doing to compare its old and new props is wasted effort
Similarly, note that rendering <MemoizedChild><OtherComponent /></MemoizedChild> will also force the child to always render, because props.children is always a new reference.
Optimizing Props References 🔗︎
Class components don't have to worry about accidentally creating new callback function references as much, because they can have instance methods that are always the same reference. However, they may need to generate unique callbacks for separate child list items, or capture a value in an anonymous function and pass that to a child. Those will result in new references, and so will creating new objects as child props while rendering. React doesn't have anything built-in to help optimize those cases.
For function components, React does provide two hooks to help you reuse the same references: useMemo for any kind of general data like creating objects or doing complex calculations, and useCallback specifically for creating callback functions.
Memoize Everything? 🔗︎
As mentioned above, you don't have throw useMemo and useCallback at every single function or object you pass down as a prop - only if it's going to make a difference in behavior for the child. (That said, the dependency array comparisons for useEffect do add another use case where the child might want to receive consistent props references, which does make things more complicated.)
The other question that comes up all the time is "Why doesn't React wrap everything in React.memo() by default?".
Dan Abramov has repeatedly pointed out that memoization does still incur the cost of comparing props, and that there are many cases where the memoization check can never prevent re-renders because the component always receives new props. As an example, see this Twitter thread from Dan:
Why doesn’t React put memo() around every component by default? Isn’t it faster? Should we make a benchmark to check?
Ask yourself:
Why don’t you put Lodash memoize() around every function? Wouldn’t that make all functions faster? Do we need a benchmark for this? Why not?
Also, while I don't have a specific link on it, it's possible that trying to apply this to all components by default might result in bugs due to cases where people are mutating data rather than updating it immutably.
I've had some public discussion with Dan about this on Twitter. I personally think it's likely that using React.memo() on a widespread basis would likely be a net gain in overall app rendering perf. As I said in an extended Twitter thread last year:
The React community as a whole seems to be over obsessed with "perf", yet much of the discussion revolves around outdated "tribal wisdom" passed down via Medium posts and Twitter comments rather than based on concrete usage.
There's definitely collective misunderstanding about the idea of a "render" and the perf impact. Yes, React is totally based around rendering - gotta render to do anything at all. No, most renders aren't overly expensive.
"Wasted" rerenders certainly aren't the end of the world. Neither is rerendering the whole app from the root. That said, it's also true that a "wasted" rerender with no DOM update is CPU cycles that didn't need to be burned. Is that a problem for most apps? Probably not. Is it something that can be improved? Probably.
Are there apps where default "rerender it all" approaches aren't sufficient? Of course, that's why sCU, PureComponent, and memo() exist.
Should users wrap everything in memo() by default? Probably not, if only because you should think about your app's perf needs. Will it actually hurt if you do? No, and realistically I expect it does have a net benefit (despite Dan's points about wasted comparisons)
Are benchmarks flawed, and results highly variable based on scenarios and apps? Of course. That said, it would be REALLY REALLY HELPFUL if folks could start pointing at hard numbers for these discussions instead of playing the telephone game of "I saw a comment once..."
I'd love to see a bunch of benchmark suites from the React team and the larger community to measure a bunch of scenarios so we could stop arguing about most of this stuff once and for all. Function creation, render cost, optimization... CONCRETE EVIDENCE, PLEASE!
But, no one's put together any good benchmarks that would demonstrate whether or not this is true:
Dan's standard answer is that app structure and update patterns vary drastically, so it's hard to make a representative benchmark.
I still think some actual numbers would be useful to aid the discussion
There's also an extended issue discussion on "When should you NOT use React.memo? in the React issues.
Note that the new React docs specifically address the "memo everything?" question:
Optimizing with
memois only valuable when your component re-renders often with the same exact props, and its re-rendering logic is expensive. If there is no perceptible lag when your component re-renders,memois unnecessary. Keep in mind thatmemois completely useless if the props passed to your component are always different, such as if you pass an object or a plain function defined during rendering. This is why you will often needuseMemoanduseCallbacktogether withmemo.There is no benefit to wrapping a component in
memoin other cases. There is no significant harm to doing that either, so some teams choose to not think about individual cases, and memoize as much as possible. The downside of this approach is that code becomes less readable. Also, not all memoization is effective: a single value that’s “always new” is enough to break memoization for an entire component.
See the details section under that link for further suggestions on avoiding unnecessary memoization and improving performance.
Immutability and Rerendering 🔗︎
State updates in React should always be done immutably. There are two main reasons why:
- depending on what you mutate and where, it can result in components not rendering when you expected they would render
- it causes confusion about when and why data actually got updated
Let's look at a couple specific examples.
As we've seen, React.memo / PureComponent / shouldComponentUpdate all rely on shallow equality checks of the current props vs the previous props. So, the expectation is that we can know if a prop is a new value, by doing props.someValue !== prevProps.someValue.
If you mutate, then someValue is the same reference, and those components will assume nothing has changed.
Note that this is specifically when we're trying to optimize performance by avoiding unnecessary re-renders. A render is "unnecessary" or "wasted" if the props haven't changed. If you mutate, the component may wrongly think nothing has changed, and then you wonder why the component didn't re-render.
The other issue is the useState and useReducer hooks. Every time I call setCounter() or dispatch(), React will queue up a re-render. However, React requires that any hook state updates must pass in / return a new reference as the new state value, whether it be a new object/array reference, or a new primitive (string/number/etc).
React applies all state updates during the render phase. When React tries to apply a state update from a hook, it checks to see if the new value is the same reference. React will always finish rendering the component that queued the update. However, if the value is the same reference as before, and there are no other reasons to continue rendering (such as the parent having rendered), React will then throw away the render results for the component and bail out of the render pass completely. So, if I mutate an array like this:
const [todos, setTodos] = useState(someTodosArray);
const onClick = () => {
todos[3].completed = true;
setTodos(todos);
};
then the component will fail to re-render.
(Note that React does actually have a "fast path" bailout mechanism that will attempt to check the new value before queuing the state update in some cases. Since this also relies on a direct reference check, it's another example of needing to do immutable updates.)
Technically, only the outermost reference has to be immutably updated. If we change that example to:
const onClick = () => {
const newTodos = todos.slice();
newTodos[3].completed = true;
setTodos(newTodos);
};
then we have created a new array reference and passed it in, and the component will re-render.
Note that there is a distinct difference in behavior between the class component this.setState() and the function component useState and useReducer hooks with regards to mutations and re-rendering. this.setState() doesn't care if you mutate at all - it always completes the re-render. So, this will re-render:
const { todos } = this.state;
todos[3].completed = true;
this.setState({ todos });
And in fact, so will passing in an empty object like this.setState({}).
Beyond all the actual rendering behavior, mutation introduces confusion to the standard React one-way data flow. Mutation can lead other code to see different values when the expectation was they haven't changed at all. This makes it harder to know when and why a given piece of state was actually supposed to update, or where a change came from.
Bottom line: React, and the rest of the React ecosystem, assume immutable updates. Any time you mutate, you run the risk of bugs. Don't do it.
Measuring React Component Rendering Performance 🔗︎
Use the React DevTools Profiler to see what components are rendering in each commit. Find components that are rendering unexpectedly, use the DevTools to figure out why they rendered, and fix things (perhaps by wrapping them in React.memo(), or having the parent component memoize the props it's passing down.)
Also, remember that React runs way slower in dev builds. You can profile your app in development mode to see which components are rendering and why, and do some comparisons of relative time needed to render components in comparison to each other ("Component B took 3 times as long to render in this commit than component A" did). But, never measure absolute render times using a React development build - only measure absolute times using production builds! (or else Dan Abramov will have to come yell at you for using numbers that aren't accurate). Note that you'll need to use a special "profiling" build of React if you want to actually use the profiler to capture timing data from a prod-like build.
Context and Rendering Behavior 🔗︎
React's Context API is a mechanism for making a single user-provided value available to a subtree of components, Any component inside of a given <MyContext.Provider> can read the value from that context instance, without having to explicitly pass that value as a prop through every intervening component.
Context is not a "state management" tool. You have to manage the values that are passed into context yourself. This is typically done by keeping data in React component state, and constructing context values based on that data.
Context Basics 🔗︎
A context provider receives a single value prop, like <MyContext.Provider value={42}>. Child components may consume the context by rendering the context consumer component and providing a render prop, like:
<MyContext.Consumer>{ (value) => <div>{value}</div>}</MyContext.Consumer>
or by calling the useContext hook in a function component:
const value = useContext(MyContext)
Updating Context Values 🔗︎
React checks to see if a context provider has been given a new value when the surrounding component renders the provider. If the provider's value is a new reference, then React knows the value has changed, and that the components consuming that context need to be updated.
Note that passing a new object to a context provider will cause it to update:
function GrandchildComponent() {
const value = useContext(MyContext);
return <div>{value.a}</div>;
}
function ChildComponent() {
return <GrandchildComponent />;
}
function ParentComponent() {
const [a, setA] = useState(0);
const [b, setB] = useState('text');
const contextValue = { a, b };
return (
<MyContext.Provider value={contextValue}>
<ChildComponent />
</MyContext.Provider>
);
}
In this example, every time ParentComponent renders, React will take note that MyContext.Provider has been given a new value, and look for components that consume MyContext as it continues looping downwards. When a context provider has a new value, every nested component that consumes that context will be forced to re-render.
Note that from React's perspective, each context provider only has a single value - doesn't matter whether that's an object, array, or a primitive, it's just one context value. Currently, there is no way for a component that consumes a context to skip updates caused by new context values, even if it only cares about part of a new value.
If a component only needs value.a, and an update is made to cause a new value.b reference... the rules of immutable updates and context rendering require that value be a new reference also, and so the component reading value.a will also render too.
State Updates, Context, and Re-Renders 🔗︎
It's time to put some of these pieces together. We know that:
- Calling
setState()queues a render of that component - React recursively renders nested components by default
- Context providers are given a value by the component that renders them
- That value normally comes from that parent component's state
This means that by default, any state update to a parent component that renders a context provider will cause all of its descendants to re-render anyway, regardless of whether they read the context value or not!.
If we look back at the Parent/Child/Grandchild example just above, we can see that the GrandchildComponent will re-render, but not because of a context update - it will re-render because ChildComponent rendered!. In this example, there's nothing trying to optimize away "unnecessary" renders, so React renders ChildComponent and GrandchildComponent by default any time ParentComponent renders. If the parent puts a new context value into MyContext.Provider, the GrandchildComponent will see the new value when it renders and use it, but the context update didn't cause GrandchildComponent to render - it was going to happen anyway.
Context Updates and Render Optimizations 🔗︎
Let's modify that example so that it does actually try to optimize things, but we'll add one other twist by putting a GreatGrandchildComponent at the bottom:
function GreatGrandchildComponent() {
return <div>Hi</div>
}
function GrandchildComponent() {
const value = useContext(MyContext);
return (
<div>
{value.a}
<GreatGrandchildComponent />
</div>
}
function ChildComponent() {
return <GrandchildComponent />
}
const MemoizedChildComponent = React.memo(ChildComponent);
function ParentComponent() {
const [a, setA] = useState(0);
const [b, setB] = useState("text");
const contextValue = {a, b};
return (
<MyContext.Provider value={contextValue}>
<MemoizedChildComponent />
</MyContext.Provider>
)
}
Now, if we call setA(42):
ParentComponentwill render- A new
contextValuereference is created - React sees that
MyContext.Providerhas a new context value, and thus any consumers ofMyContextneed to be updated - React will try to render
MemoizedChildComponent, but see that it's wrapped inReact.memo(). There are no props being passed at all, so the props have not actually changed. React will skip renderingChildComponententirely. - However, there was an update to
MyContext.Provider, so there may be components further down that need to know about that. - React continues downwards and reaches
GrandchildComponent. It sees thatMyContextis read byGrandchildComponent, and thus it should re-render because there's a new context value. React goes ahead and re-rendersGrandchildComponent, specifically because of the context change. - Because
GrandchildComponentdid render, React then keeps on going and also renders whatever's inside of it. So, React will also re-renderGreatGrandchildComponent.
In other words, as Sophie Alpert said:
That React Component Right Under Your Context Provider Should Probably Use
React.memo
That way, state updates in the parent component will not force every component to re-render, just the sections where the context is read. (You could also get basically the same result by having ParentComponent render <MyContext.Provider>{props.children}</MyContext.Provider>, which leverages the "same element reference" technique to avoid child components re-rendering, and then rendering <ParentComponent><ChildComponent /></ParentComponent> from one level up.)
Note, however, that once GrandchildComponent rendered based on the next context value, React went right back to its default behavior of recursively re-rendering everything. So, GreatGrandchildComponent was rendered, and anything else under there would have rendered too.
Context and Renderer Boundaries 🔗︎
Normally, a React app is built entirely with a single renderer like ReactDOM or React Native. But, the core rendering and reconciling logic is published as a package called react-reconciler, and you can use that to build your own version of React that targets other environments. Good examples of this are react-three-fiber, which uses React to drive Three.js models and WebGL rendering, and ink, which draws terminal text UIs using React.
One long-standing limitation is that if you have multiple renderers in an app, such as showing React-Three-Fiber content inside of ReactDOM, context providers won't pass through the renderer boundary. So, if the component tree looks like this:
function App() {
return (
<MyContext.Provider>
<DomComponent>
<ReactThreeFiberParent>
<ReactThreeFiberChild />
</ReactThreeFiberParent>
</DomComponent>
</MyContext.Provider>
);
}
where ReactFiberParent creates and shows content rendered with React-Three-Fiber, then <ReactThreeFiberChild> will not be able to see the value from <MyContext.Provider>.
This is a known limitation of React and there is currently no official way to solve this.
That said, the Poimandres org behind React-Three-Fiber has had some internal hacks that made context bridging feasible, and they recently released a lib called https://github.com/pmndrs/its-fine that includes a useContextBridge hook that is a valid workaround.
React-Redux and Rendering Behavior 🔗︎
The various forms of "CONTEXT VS REDUX?!?!??!" seem to be the single most-asked question I see in the React community right now. (That question is a false dichotomy to begin with, as Redux and Context are different tools that do different things.)
That said, one of the recurring things that people point out when this comes up is that "React-Redux only re-renders the components that actually need to render, so that makes it better than context".
That's somewhat true, but the answer is a lot more nuanced than that.
React-Redux Subscriptions 🔗︎
I've seen a lot of folks repeat the phrase "React-Redux uses context inside." Also technically true, but React-Redux uses context to pass the Redux store instance, not the current state value. That means that we always pass the same context value into our <ReactReduxContext.Provider> over time.
Remember that a Redux store runs all its subscriber notification callbacks whenever an action is dispatched. UI layers that need to use Redux always subscribe to the Redux store, read the latest state in their subscriber callbacks, diff the values, and force a re-render if the relevant data has changed. The subscription callback process happens outside of React entirely, and React only gets involved if React-Redux knows that the data needed by a specific React component has changed (based on the return values of mapState or useSelector).
This results in a very different set of performance characteristics than context. Yes, it's likely that fewer components will be rendering all the time, but React-Redux will always have to run the mapState/useSelector functions for the entire component tree every time the store state is updated. Most of the time, the cost of running those selectors is less than the cost of React doing another render pass, so it's usually a net win, but it is work that has to be done. However, if those selectors are doing expensive transformations or accidentally returning new values when they shouldn't, that can slow things down.
Differences between connect and useSelector 🔗︎
connect is a higher-order component. You pass in your own component, and connect returns a wrapper component that does all the work of subscribing to the store, running your mapState and mapDispatch, and passing the combined props down to your own component.
The connect wrapper components have always acted equivalent to PureComponent/React.memo(), but with a slightly different emphasis: connect will only make your own component render if the combined props it's passing down to your component have changed. Typically, the final combined props are a combination of {...ownProps, ...stateProps, ...dispatchProps}, so any new prop references from the parent will indeed cause your component to render, same as PureComponent or React.memo(). Besides parent props, any new references returned from mapState will also cause your component to render. . (Since you could customize how ownProps/stateProps/dispatchProps are merged, it's also possible to alter that behavior.)
useSelector, on the other hand, is a hook that is called inside of your own function components. Because of that, useSelector has no way of stopping your component from rendering when the parent component renders!.
This is a key performance difference between connect and useSelector. With connect, every connected component acts like PureComponent, and thus acts as a firewall to prevent React's default render behavior from cascading down the entire component tree. Since a typical React-Redux app has many connected components, this means that most re-render cascades are limited to a fairly small section of the component tree. React-Redux will force a connected component to render based on data changes, the next 2-3 components below it might render as well, then React runs into another connected component that didn't need to update and that stops the rendering cascade.
In addition, having more connected components means that each component is probably reading smaller pieces of data from the store, and thus is less likely to have to re-render after any given action.
If you're exclusively using function components and useSelector, then it's likely that larger parts of your component tree will re-render based on Redux store updates than they would with connect, since there aren't other connected components to stop those render cascades from continuing down the tree.
If that becomes a performance concern, then the answer is to wrap components in React.memo() yourself as needed, to prevent unnecessary re-renders caused by parent components.
Future React Improvements 🔗︎
"React Forget" Memoizing Compiler 🔗︎
Ever since React hooks first came out and we started dealing with dependency arrays for hooks like useEffect and useMemo, the React team had said they intended the hooks deps arrays to be something that "a sufficiently advanced compiler could generated automatically". In other words, use a variable named counter inside of a hook, and the compiler would automatically insert the [counter] deps array for you at build time.
Despite popping up in several discussions, the "sufficiently advanced compiler" never materialized. The community tried creating their own auto-memoization approaches like a Babel macro, but no official compiler appeared...
until ReactConf 2021, when the React team gave a talk entitled "React Without Memo". In that talk they gave a demo of an experimental compiler code-named "React Forget". It's designed to rewrite the body of function components in order to automatically add memoization capabilities.
What's really exciting about React Forget is that not only does it try to memoize hook dependency arrays, it also memoizes JSX element return values. And since we know from earlier that React has a "same-element reference" optimization that can prevent re-rendering children, this means that React Forget could, potentially, effectively eliminate unnecessary renders throughout a React component tree!.
As of October 2022, the React Forget compiler has not yet been released, but the bits of news trickling out of the React team are encouraging. Supposedly 3-4 engineers are working on building it full-time, with a goal of having Facebook.com fully working before it's released publicly for the community to try out. There's also been other hints that the work is going well - the useEvent RFC was closed on the grounds that it might not be entirely necessary if React Forget works out, and other discussions have generally suggested "what if the too many renders problem just goes away in the future thanks to auto-memoization?".
So, no guarantees at this point, but there's reason to be optimistic about the chances of React Forget panning out.
Context Selectors 🔗︎
We said earlier that the biggest weakness of the Context API is that a component cannot selectively subscribe to parts of a context value, so all components reading that context will re-render when the value is updated.
In July 2019, a community member wrote an RFC proposing a "context selectors" API, which would allow components to selectively subscribe to just part of a context. That RFC sat around for a while, and finally showed signs of life. Andrew Clark then implemented a proof of concept approach for context selectors in React in January 2021, with the new ability hidden behind an internal feature flag for experimentation.
Sadly, there has been no further movement on the context selectors feature since then. From the discussion and PR, the proof of concept version will almost definitely require changes and iteration to the API design before it could be finalized. It's also possible that this may be another feature that is semi-obsolete if the React Forget compiler works out.
If this feature actually does ever get released, it will make the Context + useReducer combo a more viable option for larger amounts of React app state.
It's worth noting that there is a useContextSelector library from Daishi Kato (maintainer of Zustand and Jotai) that may be useful as a polyfill in the meantime.
Summary 🔗︎
- React always recursively renders components by default, so when a parent renders, its children will render
- Rendering by itself is fine - it's how React knows what DOM changes are needed
- But, rendering takes time, and "wasted renders" where the UI output didn't change can add up
- It's okay to pass down new references like callback functions and objects most of the time
- APIs like
React.memo()can skip unnecessary renders if props haven't changed - But if you always pass new references down as props,
React.memo()can never skip a render, so you may need to memoize those values - Context makes values accessible to any deeply nested component that is interested
- Context providers compare their value by reference to know if it's changed
- A new context values does force all nested consumers to re-render
- But, many times the child would have re-rendered anyway due to the normal parent->child render cascade process
- So you probably want to wrap the child of a context provider in
React.memo(), or use{props.children}, so that the whole tree doesn't render all the time when you update the context value - When a child component is rendered based on a new context value, React keeps cascading renders down from there too
- React-Redux uses subscriptions to the Redux store to check for updates, instead of passing store state values by context
- Those subscriptions run on every Redux store update, so they need to be as fast as possible
- React-Redux does a lot of work to ensure that only components whose data changed are forced to re-render
connectacts likeReact.memo(), so having lots of connected components can minimize the total number of components that render at a timeuseSelectoris a hook, so it can't stop renders caused by parent components. An app that only hasuseSelectoreverywhere should probably addReact.memo()to some components to help avoid renders from cascading all the time.- The "React Forget" auto-memoizing compiler may drastically simplify all this if it does get released.
Final Thoughts 🔗︎
Clearly, the whole situation is a lot more complex than just "context makes everything render, Redux doesn't, use Redux". Don't get me wrong, I want people to use Redux, but I also want people to clearly understand the behaviors and tradeoffs involved in different tools so they can make informed decisions about what's best for their own use cases.
Since everyone always seems to ask "When should I use Context, and when should I use (React-)Redux?", let me go ahead and recap some standard rules of thumb:
- Use context if:
- You just need to pass some simple values that don't change often
- You have some state or functions that need to be accessed through part of the app, and you don't want to pass them as props all the way down
- You want to stick with what's built in to React and not add additional libraries
- Use (React-)Redux if:
- You have large amounts of application state that are needed in many places in the app
- The app state is updated frequently over time
- The logic to update that state may be complex
- The app has a medium or large-sized codebase, and might be worked on by many people
Please note that these are not hard, exclusive rules - they are just some suggested guidelines for when these tools might make sense! As always, please take some time to decide for yourself what the best tool is for whatever situation you're dealing with.
Overall, hopefully this explanation helps folks understand the bigger picture of what's actually going on with React's rendering behavior in various situations.
Further Information 🔗︎
I recorded a conference talk version of this post for React Advanced in October 2022:
I've seen several other good articles specifically covering "how does React rendering work?" recently, and I'll point to those as recommended:
- Recommended React Rendering articles:
Beyond that, see these additional resources:
- General
- React Render Behavior
- React docs: Reconciliation
- React class lifecycle methods diagram
- React hooks lifecycle diagram
- React issues: bailing out of context and hooks
- React issues: why
setStateis async - Seb Markbage: "Context is good for low-frequency updates, not Flux-like state propagation"
- Ryan Florence: React, Inline Functions, and Performance
- James K Nelson: React context and performance
- Will It Render? A visualization for component rendering
- Optimizing Render Performance
- Profiling React Components
- React-Redux Performance
This is a post in the Blogged Answers series. Other posts in this series:
- Aug 08, 2023 - Blogged Answers: My Experience Modernizing Packages to ESM
- Jul 06, 2022 - Blogged Answers: How I Estimate NPM Package Market Share (and how Redux usage compares to other libraries)
- Jun 22, 2021 - Blogged Answers: The Evolution of Redux Testing Approaches
- Jan 18, 2021 - Blogged Answers: Why React Context is Not a "State Management" Tool (and Why It Doesn't Replace Redux)
- Jun 21, 2020 - Blogged Answers: React Components, Reusability, and Abstraction
- May 17, 2020 - Blogged Answers: A (Mostly) Complete Guide to React Rendering Behavior
- May 12, 2020 - Blogged Answers: Why I Write
- Feb 22, 2020 - Blogged Answers: Why Redux Toolkit Uses Thunks for Async Logic
- Feb 22, 2020 - Blogged Answers: Coder vs Tech Lead - Balancing Roles
- Jan 19, 2020 - Blogged Answers: React, Redux, and Context Behavior
- Jan 01, 2020 - Blogged Answers: Years in Review, 2018-2019
- Jan 01, 2020 - Blogged Answers: Reasons to Use Thunks
- Jan 01, 2020 - Blogged Answers: A Comparison of Redux Batching Techniques
- Nov 26, 2019 - Blogged Answers: Learning and Using TypeScript as an App Dev and a Library Maintainer
- Jul 10, 2019 - Blogged Answers: Thoughts on React Hooks, Redux, and Separation of Concerns
- Jan 19, 2019 - Blogged Answers: Debugging Tips
- Mar 29, 2018 - Blogged Answers: Redux - Not Dead Yet!
- Dec 18, 2017 - Blogged Answers: Resources for Learning Redux
- Dec 18, 2017 - Blogged Answers: Resources for Learning React
- Aug 02, 2017 - Blogged Answers: Webpack HMR vs React-Hot-Loader
- Sep 14, 2016 - How I Got Here: My Journey Into the World of Redux and Open Source